
Reinforcement Learning
At FRPG, we investigate reinforcement learning (RL) based methods for aerial robot control. This ranges from low-level control to high-level guidance. A special emphasis is put on developing hybrid approaches combining RL and classical control to preserve stability properties. Another key focus is on interpretability of the RL policy and hyper-parameter selection.
RL-based Formation Control: For many complex perception problems, such as human or animal MoCap, it is hard to model a reliable objective function that models the perception
uncertainty. These models can not only be difficult to derive but also highly non-convex. We therefore take a deep RL approach to solve the perception-driven formation control problem. The key
idea is to model the problem as a sequential decision making problem and learn optimal policies for each robot/agent in the team that maximizes the joint MoCap accuracy -- embedded as rewards
only during training. For human MoCap, we learned navigation policies for multiple aerial robots purely in simulation and deploy on real robots. Here observations were joint detections on 2D
images obtained by the robots. Ongoing work involves end-to-end DRL methods that overcome the need for joint detections, and DRL approach for animal MoCap.
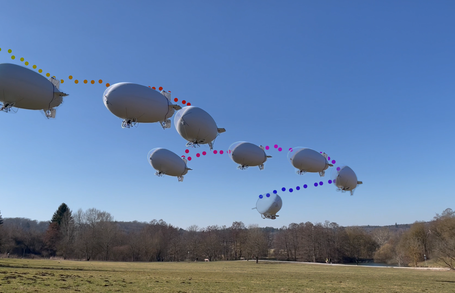
RL-based Guidance and Control: In this context we develop various RL and DRL-based methods ranging from airship control, autonomous landing of multi-rotors on moving platforms, autonomous soaring of gliders, and collision avoidance in large teams of robots. For airship control, we have developed a DRL method that combines a classical PID with learning and leverages PID's stability properties. For autonomous landing, our RL approach learns an optimal policy for 2D horizontal motion of the robot, with a special focus on interpretable hyper-parameter derivation. For autonomous soaring, we develop DRL based approaches that maximize the exploitation of updrafts and balance it with a simultaneous waypoint navigation task. In the context of collision avoidance, we explore attention networks that allow scalability to a very large number of robots and interpretability of the RL policy.